
Contents
データベースの形式のオープンデータ
データ分析の学習やアルゴリズムの検証をする時に、オープンデータを良く用います。例えば、テーブルデータなら、アイリスのデータセットやタイタニック号の生存者のデータセット、画像データならCIFARやcocoといったものが挙げられます。
幅広くビジネスをとらえた時に、もっともメジャーに取り扱うことが多いのはやはりテーブル形式のデータでしょう。比較的にデータが整備されている大きい企業ではデータベースがあり、リレーショナルデータベース形式のデータが普段使われると思います。
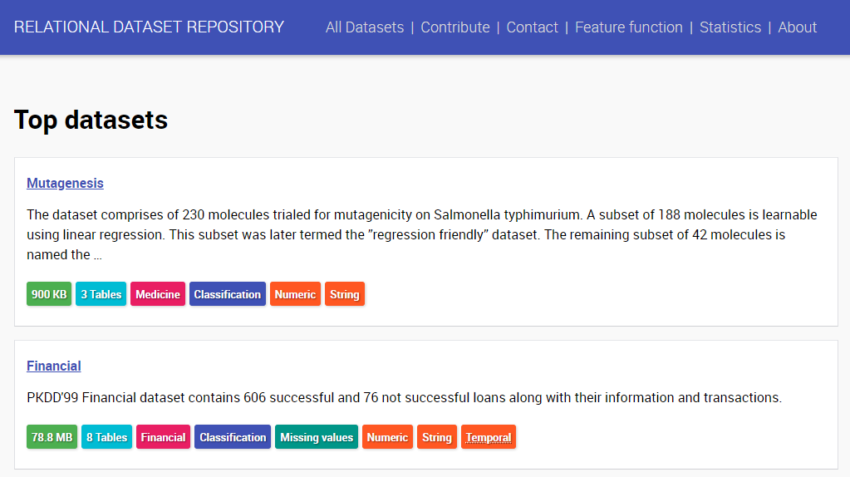
このようなリレーショナルデータベース形式になっているオープンデータのリポジトリであるRELATIONAL DATASET REPOSITORYをご紹介します。
RELATIONAL DATASET REPOSITORYの特徴を挙げると以下です。
- エンタープライズのデータベースと同様リレーショナルデータベース(RDB)形式になっている
- 機械学習の予測タスクに即したターゲットが定義できるデータセットになっている
- データサイズ、テーブル数、データの関連分野、予測タスクの種類、データモデル等豊富なメタ情報を用いてほしいデータセットを探すことができる
なぜ上記の特徴がうれしいのか。一般に何かを検証するときにオープンデータを用いますが、しばしばオープンデータですと、以下の理由で便利な反面、実際のデータに即した開発とかけ離れてしまうことがあります。
- データがクレンジングされ、一つのテーブルにまとまっている。そのため、テーブルの結合操作といった実現場では発生する処理を想定できない
- 複数のテーブルがあっても、統計データのように、単に統計データが複数のテーブルになっているだけでリレーショナルデータではない
- 予測タスクが定義できないため、機械学習等の開発検証に用いることができない
一方、社内データを実際に使うとなると、実際にデータ量の問題であったり、個人情報などセンシティブな情報が含まれていたりと、気軽な検証で用いるにはそれなりのハードルがあるのです。
どんなデータがあるか探してみる
早速どのようにデータセットを探すか見てみましょう。
トップにあるメニューで「All Datasets」を選択します。
すると、左側にチェックボックスが現れ、様々な条件でフィルタリングすることが可能です。
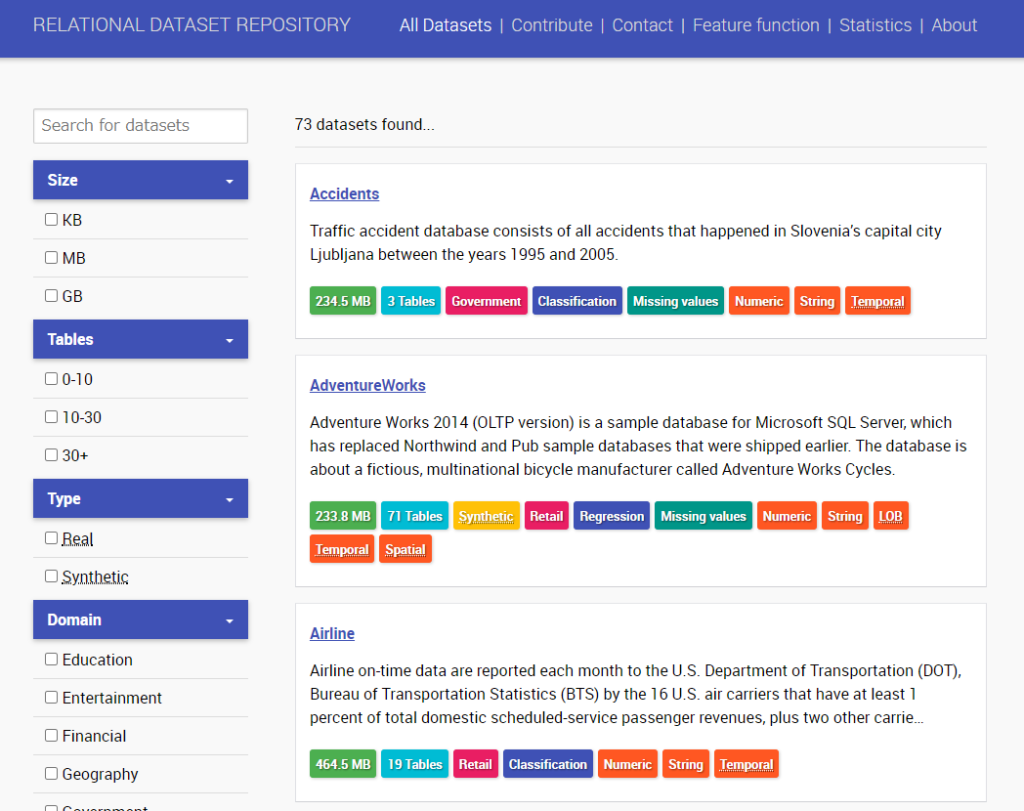
例えば、リレーショナルデータベースのデータで、テーブル数が10以上あり、小売りに関連した回帰タスクに使えるデータセットがないか探したいときも、左側のメニューにあるチェックボックスを選ぶことでデータセットが絞り込まれます。このような条件で、実際に絞り込みをすると以下のようなデータセットが候補として得られました。
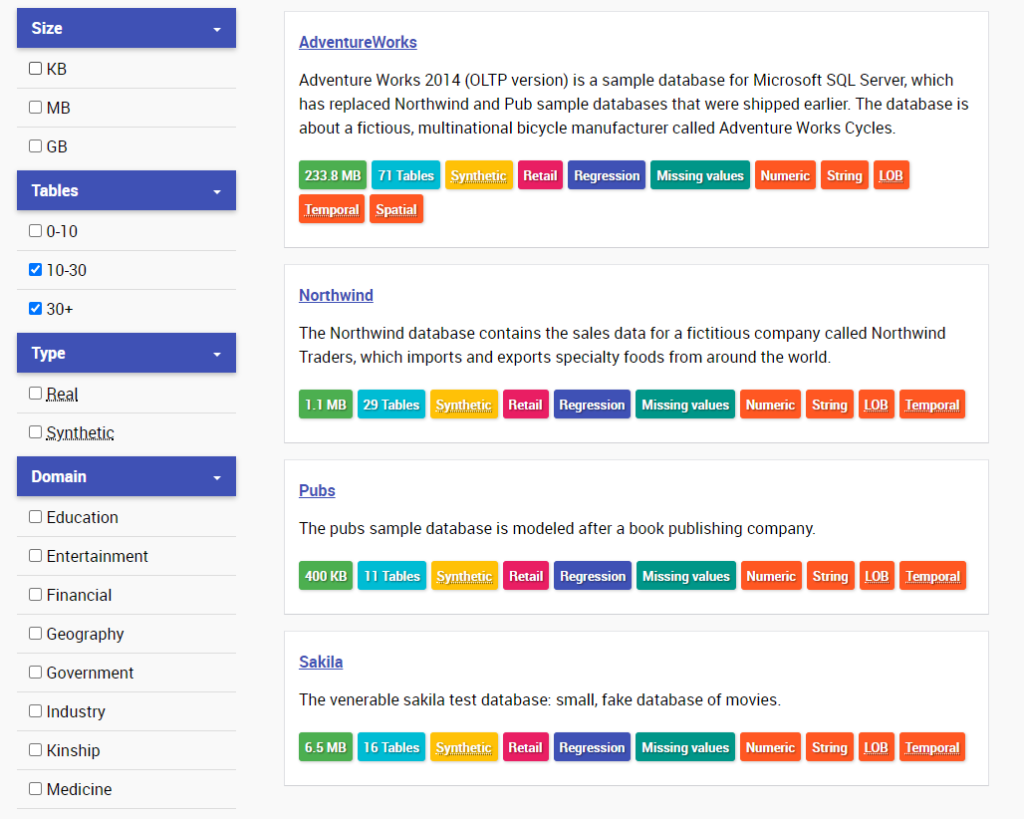
データセットの特徴が、わかりやすいタグでハイライトされている点もすごく評価できます。一番上に来ているAdventureWorksは知る人ぞ知る有名なMicrosoftが提供しているサンプルデータベースですね。
このAdventureWorksのデータセットは、Microsoftのウェブページにいけば、データベースのバックアップファイルをダウンロードして、SQL Server Management Studioでリストアすれば使えるようになります。
そうです。AdventureWorksのデータに関しては、RELATIONAL DATASET REPOSITORYでなくても入手することができます。ですが、このリポジトリが便利なところは、異なる出展元が作成しているデータベースのデータセットを同じプラットフォーム上で検索できるようにし、後述するようにMySQL workbenchですべて操作できるようにしている点にもあります。
データセットの詳細ページの中身
上で出てきたデータセットのさらに詳細な情報は個別のページにまとめられていますので、データセット名のリンクをクリックして見てみます。
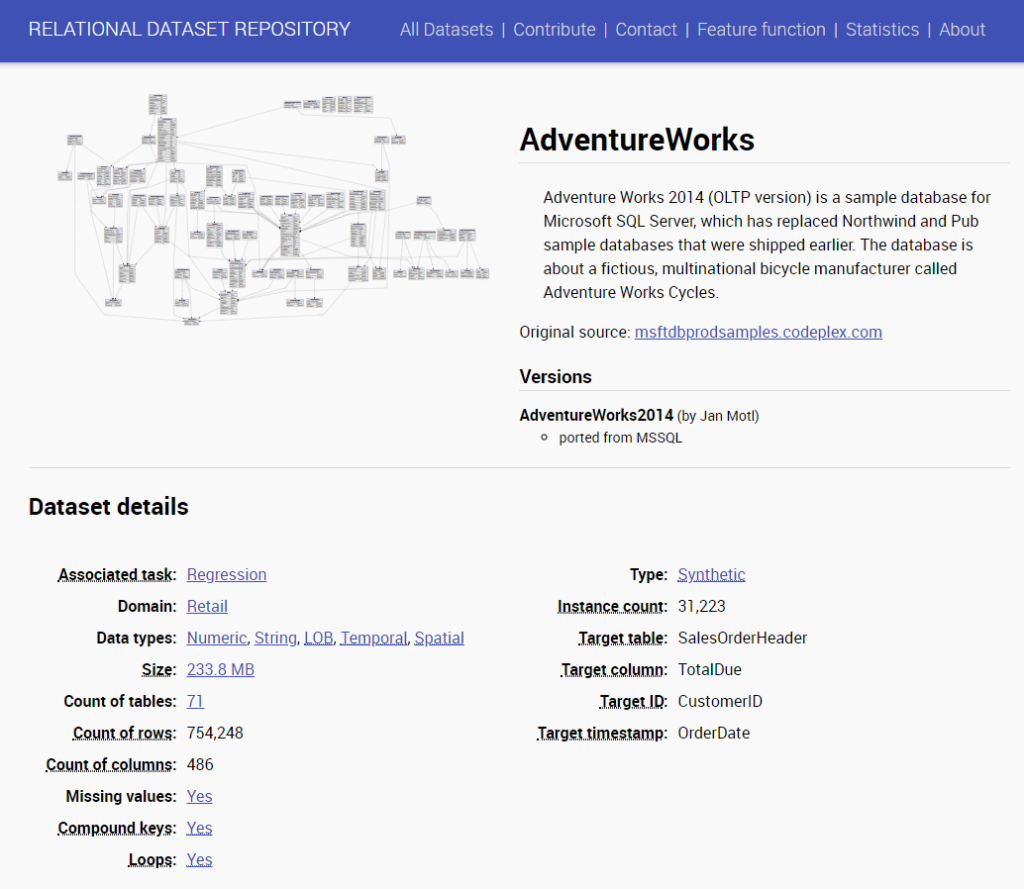
Dataset detailsの部分には、非常に親切に様々なメタ情報を示しています。
関連している機械学習タスク、データのドメイン、データサイズ、テーブル数、データの行数、ターゲット等々。
実際にデータベースを触る準備をする
自分のパソコンでも簡単にデータベースに接続してたたくことができるため、その準備の方法について紹介します。
今回は以下のような環境でインストールを行い、データベース操作を行いました。
OS:Windows 10 Home edition 64 bit
データベースに接続するためには、いくつかソフトウェアのインストールが必要になるが、以下の内容です。
- Visual Studio 2015、2017、および 2019 用 Microsoft Visual C++ 再頒布可能パッケージ (自分の環境では、「x86: vc_redist.x86.exe」をインストール)
- MySQL workbench (対応するOSのものを選択する)
インストールが完了したら、MySQLのworkbenchを起動し、データベースとの接続を行います。
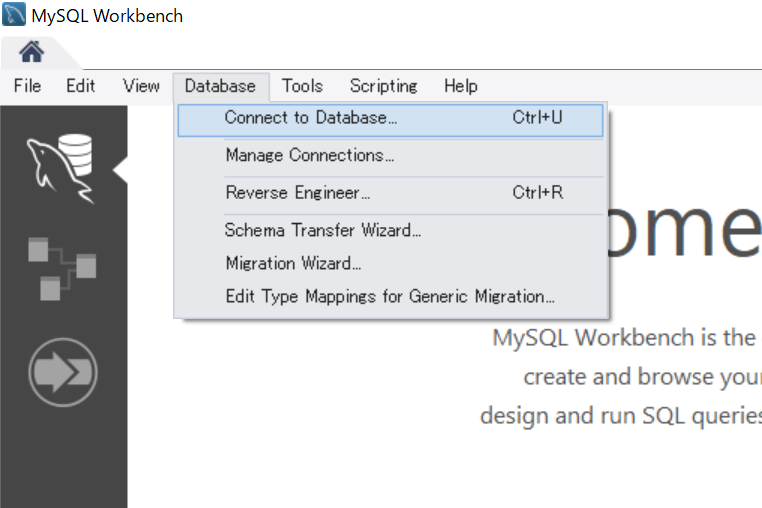
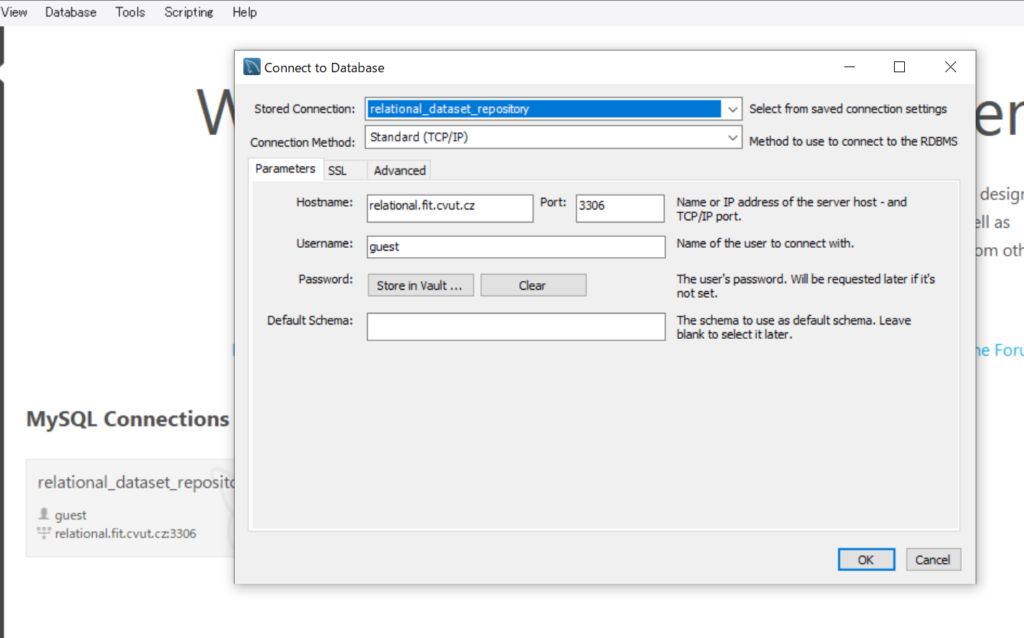
新たに、ウィンドが立ち上がりますので、「Stored Connection」のところに任意の接続名称を付けます。それから、Hostnameをrelational.fil.cvut.czとし、Portを3306、そして、Usernameをguestに設定の上、OKをすれば新たな操作画面が立ち上がります。
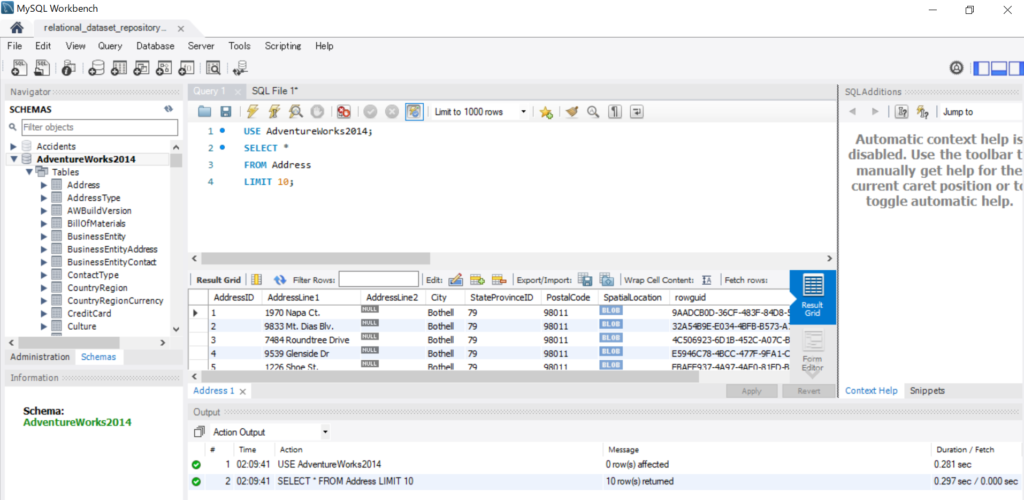
操作画面では、異なるデータセットがそれぞれ異なるスキーマ―になっています。
RELATIONAL DATASET REPOSITORYの作者
リポジトリのページのアドレスにもありますように、CVUT、つまりチェコ工科大学の情報技術学部の研究者が作成してます。チェコ工科大学は歴史あるチェコ共和国の名門校で、ノーベル賞受賞者も輩出しています。
参考資料
The CTU Prague Relational Learning Repository
最後に
英語のリソースのため、日本ではほぼ知られていないようです。調べてみた限りなぜかはわかりませんが、英語圏でもそこまで有名ではないようですね。
Kaggleのデータセットに比べて操作性とデータの品質、現場に即したリアルなリレーショナルデータベースであることを考えると非常に優れているため、もっと有名になってほしいところです。
また、MySQLのworkbenchで接続できるため、自宅のパソコンで気軽にデータベース遊びやSQLの練習ができるのも非常に魅力的な点です。
皆さんもぜひ試してみてください。
なお、利用に関するライセンスは引用手法以外特に明記されていませんが、念のため個別のデータセットは別の出典元があるためそこでも確認した方が無難でしょう。AdventureWorksなどはMITライセンスで問題なく二次利用が可能でした。
 (まだ評価がありません)
(まだ評価がありません)